|
Stable Diffusion 和 Midjourney的简单介绍 SD和Mid都属于能够通过prompt(提示词)来进行文生图,或是图生图的方式来生成想要的图片,但在很多具体的部分有很大的差异。本篇会对两个软件都进行介绍,再对比不同之处。 Stable Diffusion是2022年发布的深度学习文本到图像生成模型,它是一种潜在扩散模型,它由创业公司Stability AI与多个学术研究者和非营利组织合作开发。目前的SD的源代码和模型都已经开源,在Github上由AUTOMATIC1111维护了一个完整的项目,正在由全世界的开发者共同维护。 由于完整版对使用者的要求较高,因此目前国内有多位开发者维护着一些不同版本的封装包。其中,B站的秋叶大佬的封装包使用的最为广泛。大佬们为SD的普及做出了难以磨灭的贡献。 SD最大的特征,就是由于其开源的特性,可以在电脑本地上离线运行。可以在大多数配备至少4GB显存的适度GPU的消费级硬件上运行。推荐的显存是8G及以上。 Stable Diffusion界面如下: 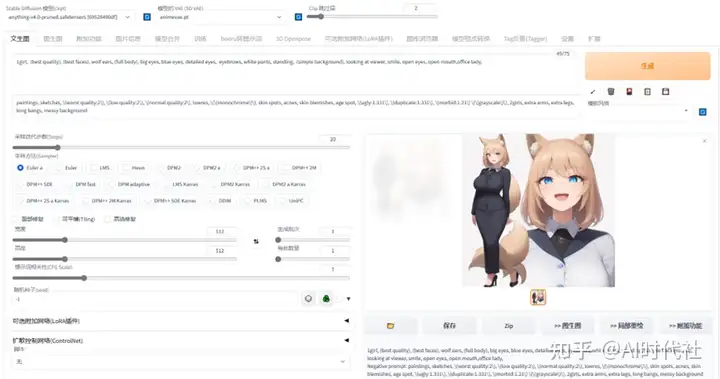 Midjourney是一款由总部位于旧金山的独立研究实验室Midjourney, Inc.创建和托管的人工智能程序和服务。Midjourney基于Discord平台提供服务,可以根据自然语言描述(称为“提示”)生成图像,也支持图生图功能。使用Mid需要登陆Discord账号,在聊天界面发送指令后就可以直接在线得到AI图像。 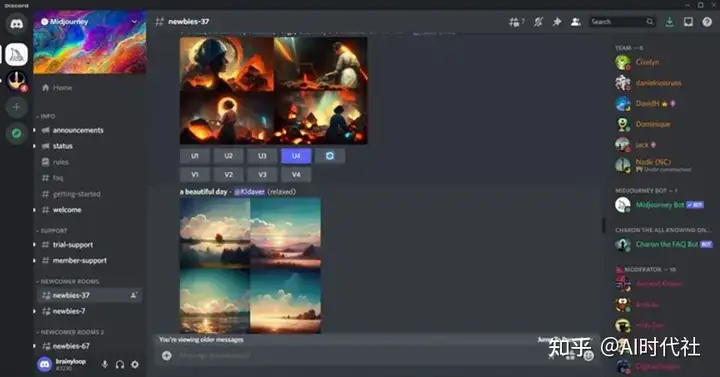 Stable Diffusion主要特征 Stable Diffusion主要特征①硬件要求较高:需要本地的独立显卡,对硬件要求高。纯CPU也能跑,但是速度会非常慢。 ②部署相对麻烦:按照官方的指导的话,环境布置略微麻烦,需要从GitHub下载很多文件,且要求一定的python知识,但如使用国内技术大牛打包的整合包就会简单很多。 ③有一定的使用难度:SD的界面有很多内容,如采样方式等,上手很简单,但想玩好以及训练自己的模型等都需要比较复杂的学习过程。 ④上限很高/下限低:无特殊操作的情况下,SD可能跑出古神。需要有一定的学习过程才能跑出好看的图片,但是图片如果好看,又可以做到非常精致。易上手,难精通,但是精通之后上限极高。 ⑤可控性极强,功能性极强:插件极多,LORA极多,可以几乎随心所欲地换风格和形态,出图的数量也极大。可以完成很多有生产力的工作。 ⑥可完全本地运行:运行全程可无需联网,数据仅存在本地,拥有硬件即可无限使用。 ⑦【极其重要】可以训练模型:可以“炼丹”,训练只属于自己的数据库,让AI完全按照自己的想法去塑造目标风格的内容。 ⑧本地化部署完毕后可完全免费无限次使用。 Midjourney主要特征①无硬件要求:但需要科学上网,需要注册discord。不过,对本地硬件性能0要求,可以在几乎所有设备上运行。 ②部署较为简单:下载discord,注册后,稍微学习一下就能使用(后面我们会出教程),门槛相对较低。 ③使用难度较低:基本上复制别人已有的提示词,选好选项,就能出图。 ④上限低/下限高:无特殊操作的情况下,Mid也能够立刻产出比较讨喜的图片。但是能够把控的范围也更小。容易上手,容易精通,但是精通之后上限比较低。 ⑤可控性极弱:没有插件,没有LORA,产出的画面风格非常固定,自由度较低。 ⑥必须联网运行:运行全程联网,数据存在服务器上,本地保存相对麻烦,必须科学上网。 ⑦无法自定义自己想要的模型:只能用官方提供的。 ⑧收费昂贵,每月60美元才能达到较好的效果。 总结直观的来说,啥都不会的人,哪怕复制别人的提示词,SD的用户得到的图片可能也会较为粗糙。 Mid用户只要复制别人已有的提示词,一开始就能得到相对精美的图片。 但是到后面,随着能力的提升,SD用户能够随心所欲地训练自己的模型和LORA,乃至引入ControlNet用各类工具来控制AI绘画出图的内容。甚至还可以指定区域重绘……这个过程最终就会很像真实的绘画。 简单来说,SD是在本地运行的服务,开源,但门槛较高,但是能够实现的效果上限极高。而Mid作为在线的服务,门槛低,但是可控性不够强,上限低。 SD和Mid我都高强度用了一段时间,但我还是坚持选择SD。因为SD可以训练自己想要的模型,并且完全掌控。虽然炼模型比较麻烦,其中涉及到很多参数调整和素材,非常复杂,但是这个过程走完之后得到的模型能够成为自己的美术资产。今后的世界里,只属于自己的模型或许是公司/个人的重要资产,是竞争力,也是壁垒。
| 
 发表于 2023-8-16 22:57:45
发表于 2023-8-16 22:57:45
 发表于 2023-8-26 15:10:27
发表于 2023-8-26 15:10:27
